Modern Lean theorem provers achieve strong performance only with substantial training and
inference compute. This cost is driven in part by the scarcity of verified proof data and by
the long reasoning traces required for formal proof search, which make both supervised
fine-tuning and sampling expensive. We introduce Pythagoras-Prover, a compute-efficient
open-source family of Lean theorem provers designed to deliver strong performance under
practical compute budgets. The family spans two generation paradigms: two autoregressive
models with 4B and 32B parameters, and a first proof-of-concept diffusion-based
theorem-proving model (4B), which iteratively refines Lean proofs at inference time. To make
training more efficient, we construct a Lean-verified corpus stratified into easy, medium, and
hard problems and use it for curriculum supervised fine-tuning, allowing the models to acquire
proof skills progressively from shorter and simpler proofs to longer and more difficult ones.
During supervised fine-tuning, we further apply a dynamic proof-reasoning filtering
scheme that preserves informative proof traces while ensuring each training instance fits
within an 8k-token context budget. We further introduce Augmented Lean Formalisation
(ALF), which expands scarce verified corpora into variants of formal statements; these variants
are then populated through self-distillation, providing additional training signal without
requiring every mutated instance to be formally verified. By perturbing known problems while
preserving their formal character, ALF exposes the model to structured variants of verified
problems, reducing reliance on any single statement’s surface form. Empirically,
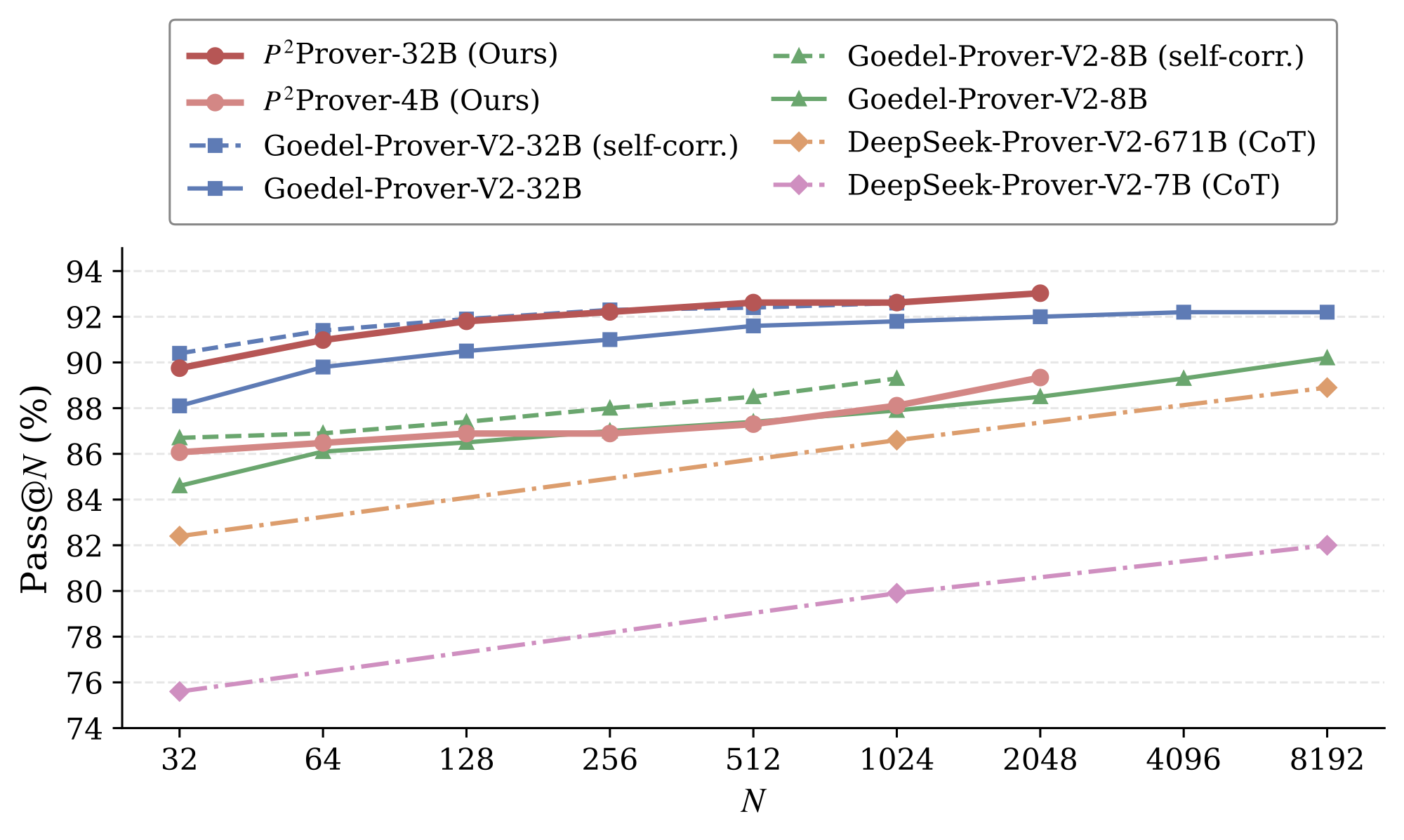
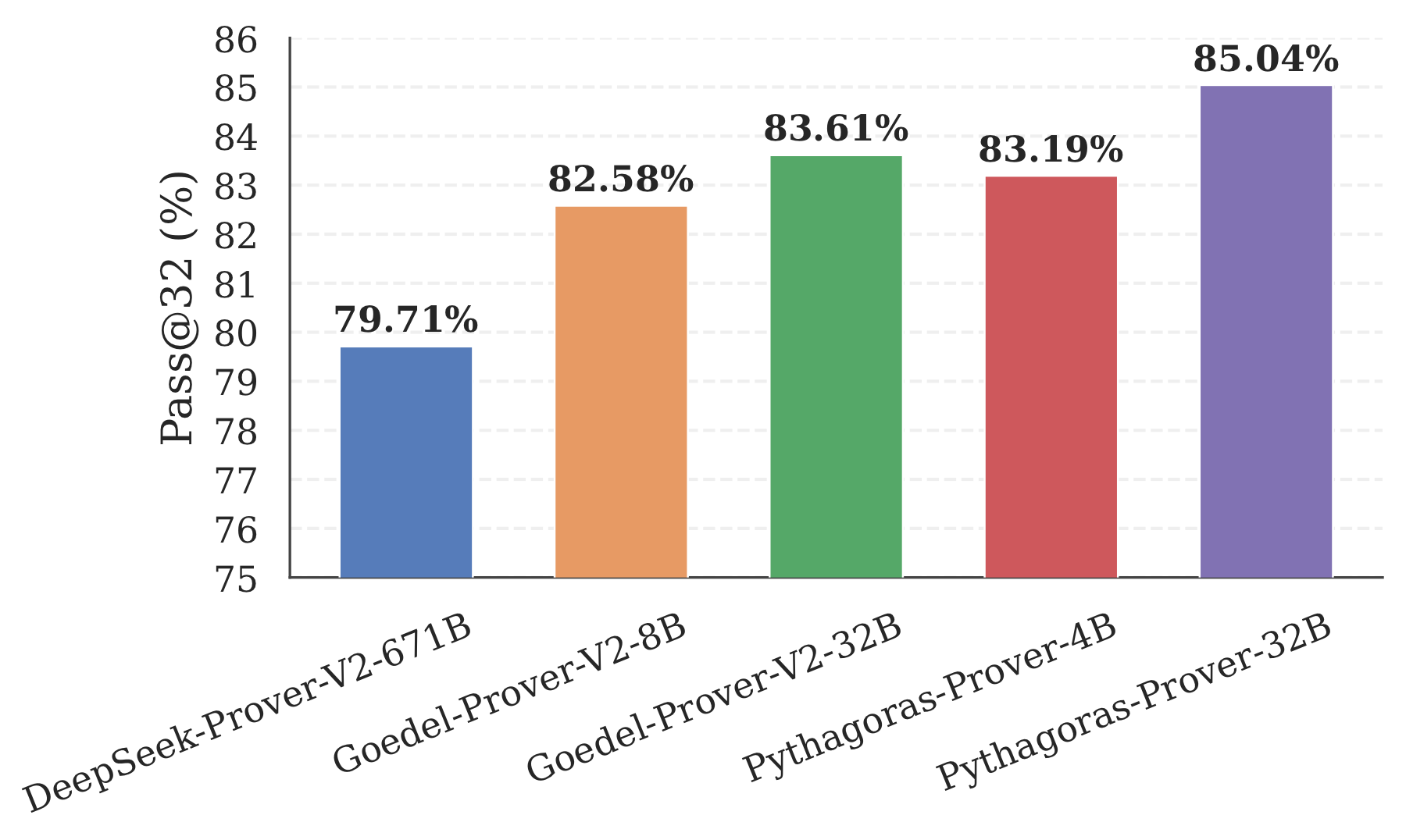
Pythagoras-Prover demonstrates strong performance across model scales. Most notably,
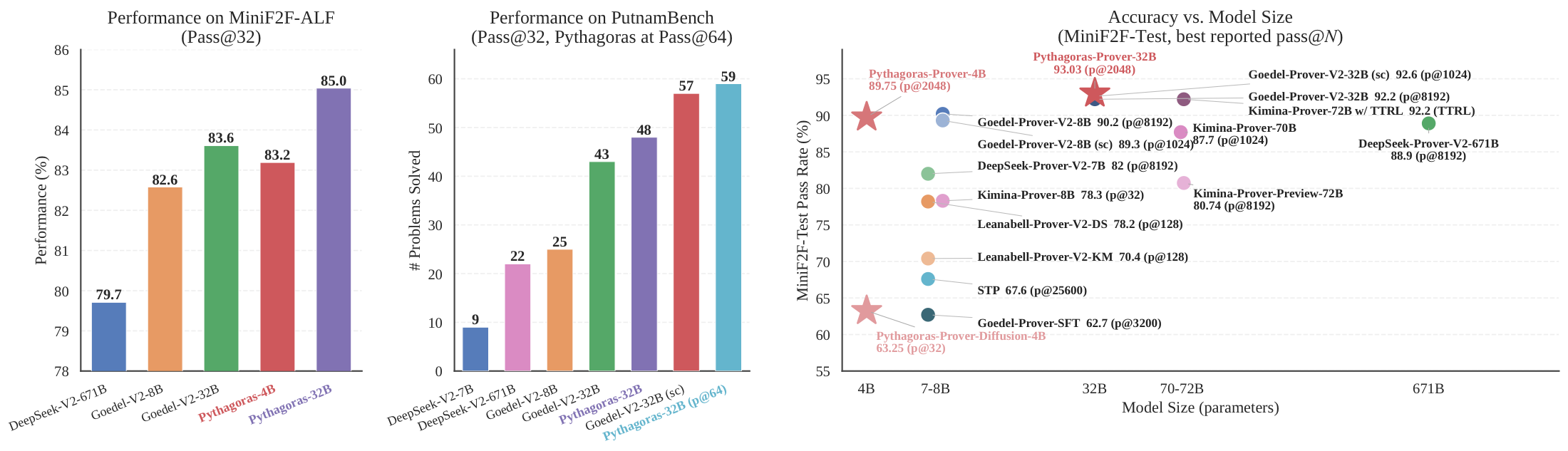
Pythagoras-Prover-4B surpasses DeepSeek-Prover-V2-671B at pass@32 on MiniF2F-Test
(82.4% → 86.1%), despite using roughly 167× fewer parameters. Scaling to 32B
further yields state-of-the-art performance among open-source neural theorem provers, with
Pythagoras-Prover-32B attaining 93.0% on MiniF2F-Test and solving 93 of 672 problems on
PutnamBench. We additionally release MiniF2F-ALF, an ALF-mutated
contamination-sensitive perturbation benchmark on which every evaluated model loses accuracy;
on this split, Pythagoras-Prover-32B remains the strongest evaluated prover, while
Pythagoras-Prover-4B reaches parity with Goedel-Prover-V2-32B, the prior state of the art.
Together, these results show that strong Lean theorem proving need not rely exclusively on
frontier-scale models.